How to Model Workflows in REST APIs
REST Services are awesome for performing basic CRUD operations on database tables, but they get even more exciting when you realize that they can also be used for modeling workflows and other advanced scenarios.
To show this point, let’s take the blog post workflow below and expose it as a RESTful Web Service:
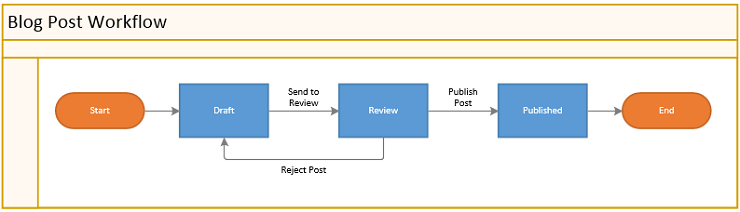
There are lots of ways you can implement this, so in the following sections we will try three different approaches and take a look at the pro’s and con’s of each of them.
Let’s get started!
1. Use an Attribute for the Workflow’s State
The easiest way to model the blog workflow is just to store the workflow state as an attribute on the blog post resource:
{
"id": 54301,
"status": "Draft",
"title": "7 Things You Didn’t Know about Star Wars",
"content": "George Lucas accidentally revealed that…"
}
If a client wants to move the blog post to a new state, it just updates the status attribute to the desired state.
It’s an easy solution and the popular blogging software WordPress is basically using this approach in their REST API.
But when you start to dig deeper into it, you realized that it comes with some serious drawbacks.
The first is that the front-end engineer who writes the client code is forced to search through the API documentation to see what values can be used in the status attribute. This conflicts with the idea that REST Services should be self-describing and not relying on out-of-band documentation.
But this drawback can be fixed by adding a metadata service where the client can get a list of all legal values for the status attribute.
A more serious drawback is that the engineer also needs to look in the API documentation to see what workflow transitions are possible (i.e. can you jump directly from Draft to Published?) and code all these workflow rules in the client code.
This means that business logic is leaking into the client, so if there are many different types of clients (mobile apps, websites, etc.) then each client will be forced to re-implement the workflow logic in their own code, which is not a cost-effective way to do software development.
But even worse, it breaks the fundamental software engineering principle of Don’t Repeat Yourself (DRY) and it violates the separation of concerns between the client and server, which makes it even harder to maintain and evolve the software.
2. Use Hyperlinks for Workflow Transitions
So what should you do if you have transition rules in your workflow, but you don’t want all the bad stuff I mentioned in the previous section?
An alternative approach is to model each workflow transition as a subresource and let clients to use HTTP’s POST method on these subresources to perform the transition. This is inspired by the action pattern in PayPal’s API Standards.
On top of the subresources, you add hyperlinks in the response to let the client know what workflow transitions are possible in the current state.
So with this approach, the response will look like this:
{
"id": 54301,
"status": "Draft",
"title": "7 Things You Didn’t Know about Star Wars",
"content": "George Lucas accidentally revealed that…",
"_links": {
"sendToReview": {
"description": "Send to Review",
"href": "/posts/54301/review"
}
}
}
The smart thing is that the _links section is automatically updated to show what workflow transitions are available in the current state. So in the example above, you can see that the blog post is in the Draft state, and from there you can make the Send to Review transition to move the post to the Review state.
So if you call POST /posts/54301/review, you move the blog post to the Review state, and then the server will update the _links section to show what workflow transitions are possible in this new state:
{
"id": 54301,
"status": "Review",
"title": "7 Things You Didn’t Know about Star Wars",
"content": "George Lucas accidentally revealed that…",
"_links": {
"publishPost": {
"description": "Publish Post",
"href": "/posts/54301/publish"
},
"rejectPost": {
"description": "Reject Post",
"href":"/posts/54301/reject"
}
}
}
The benefit of this solution is that clients no longer need to implement workflow logic in their own code, which means that business logic is no longer leaked into them.
It also reduces the risk of poorly constructed links in the client code — which is a frequent cause of defects in REST clients — because the clients get the links from the server.
Another really cool thing is that if the client needs to display a Next Action menu, it can simply loop through the values in the _links section and use them as menu items.
Finally, it also fits nicely with REST’s goal of self-discovery and HATEOAS.
The drawback compared to the approach in the previous section is that the response is bigger, because it includes the _links section. Another drawback is that the interaction between the client and server has become a little more chatty, because you now need two requests if you want to update a blog post and send it to review.
But I think both of these drawbacks are pretty minor compared to what you get out of it.
A more serious concern is that if you have an advanced workflow, you might end up with a massive number of subresources (i.e. one for each workflow state), which might look a bit messed up.
Another concern is that the server will need to know all states at design time to create subresources for them. This won’t be a problem for most workflows, but if you offer sophisticated workflow functionality where users can customize the states and transitions to fit their special needs it could be problematic.
3. Use a Subresource for Workflow Transitions
So how do you model customizable workflows?
For inspiration, let’s take a look at the issue-tracking tool JIRA, which allows (admin) users to configure their own workflows at runtime. How do they expose this in their REST API?
On their issue resource, they added a transitions subresource where the client can get a list of possible transitions from the issue’s current state. The client can then take one of these possible states and make a POST to the same subresource to transit to that state.
I like their approach, but think it’s a little naughty that they use the same subresource for two different things (i.e. list potential states, and change the current state).
So to use this approach for our blog post workflow, you can add a subresource with potential transition changes (you could also call it “transactions“ or “actions“ depending on your preferences):
GET /posts/{id}/availableTransitions
For a blog post in the Review state, it will return something like this:
[
{"transition":"Publish Post"},
{"transition":"Reject Post"}
]
If you want to do a transition, you grab one of the possible transitions from the array and POST it to the transitions subresource:
POST /posts/{id}/transitions
{
"transition": "Publish Post"
}
A cool thing about this approach is that if you need more advanced workflow transitions, you can add more attributes to the transition subresource. For example, when you transit to the Review state, you might also want to specify a reviewer and a comment:
POST /posts/{id}/transitions
{
"transition": "Send to Review",
"reviewer": "Han Solo",
"comment": "Plz review this faster than you did the Kessel Run!"
}
Another interesting possibility is that if the history of transitions is important (for audit), you could enable a GET method on the transitions subresource to get a full list of all transitions that have been performed on the resource.
You could also decide to execute the transitions asynchronous by returning a 202 Accepted status code and a link where the client can poll the latest status. This could be useful in a money transfer between banks where the actual transfer happens in a nightly batch.
Prakash Subramaniam even goes as far as playing with the idea that you should drop PUT all together, and only allow changing resources through a transition subresource. The good thing is that it neatly separates the interface into a query and command part (as per the CQRS pattern) and you have a strong audit trail of what has happened to the resource.
The drawback is that there are (many) scenarios where it’s total overkill to perform a transaction. For example, to edit the title of a blog post. A live blog post editor would probably end up doing so many transactions that it would overwhelm any kind of history log. But for something like a bank account, it makes good sense to make each update inside a transaction, so you have a complete audit trail.
So which one should I pick?
So we came to the unavoidable question: What approach is the best one?
As always, it depends on the context, but here are some quick guidelines:
| STYLE | USE WHEN: |
| 1. State Attribute | When there are no restrictions on the transitions. You can go from any state to any state at any time. The states are basically nothing more than a list of values. |
| 2. Transition Links | There are limits to which states you can go to depending on the current state. |
| 3. Transition Subresource | The workflow is configurable by users, so states and transitions among them are not fixed, but can be changed at runtime. |
So use the Einstein rule (i.e. make things as simple as possible, but not simpler) and start with the first approach, and only consider number two or even number three if there is an undeniable need for them.
That’s all for now. Thank you for reading!