The Circuit Breaker Pattern
When we start using external services in our code, we introduce a whole new range of potential problems, such as timeouts and service unavailability, that we don’t need to deal with when using in-memory API calls.
For example, a web shop can be designed to scale automatically to handle peak loads, such as Black Friday, but if its core business process depends on an external service that breaks under unexpected loads, then the whole web shop can be brought to its knees, unless we design for this situation.
One of the best ways to address this problem is to use the circuit breaker pattern, which stops all calls to an external service when that service is unavailable and then the circuit breaker returns an artificial response instead (more on that later).
In the Java-based NewsReader example in the previous blog post, we can add a circuit breaker as a decorator around the Feed interface as seen in the diagram below:
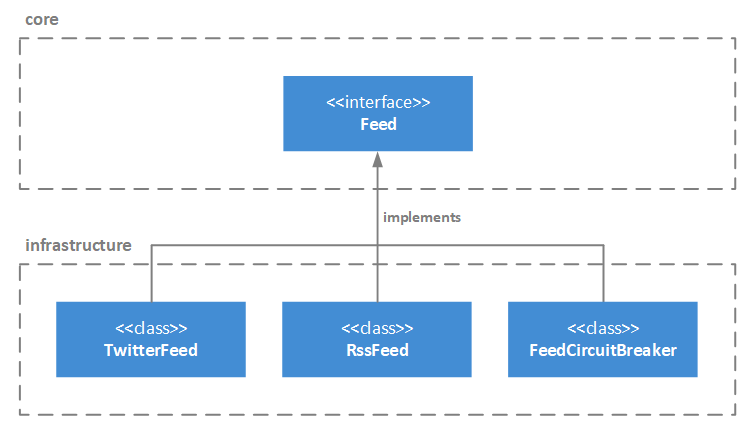
A pseudocode implementation of the FeedCircuitBreaker class is shown below:
public final class FeedCircuitBreaker implements Feed {
private Feed feed;
private List<Post> cache = Collections.emptyList();
private boolean circuitOpen = true;
private LocalDateTime circuitRetry;
public FeedCircuitBreaker(Feed feed) {
this.feed = Objects.requireNonNull(feed);
}
@Override
public List<Post> getPosts() {
// Is it time to reopen the circuit and try again?
if(!circuitOpen && LocalDateTime.now().isAfter(circuitRetry)) {
circuitOpen = true;
}
if(circuitOpen) {
try {
cache = feed.getPosts();
} catch(Exception e) {
// Close the circuit and wait 5 minutes before trying again
circuitOpen = false;
circuitRetry = LocalDateTime.now().plusMinutes(5);
}
}
return cache;
}
}
And using the circuit breaker is a matter of decorating an underlying feed:
Feed f = new FeedCircuitBreaker(new TwitterFeed("@KennethLange"));
The tricky part of the circuit breaker pattern is to design the right fallback strategy where we need to decide what will happen when the external service is unavailable. There are many different fallback strategies we can choose from, and some of the most common ones are shown below:
- Crash and burn: We assume errors will not occur and don’t design for it. For example, we have all seen websites where raw PHP errors are shown directly in the HTML returned to the end users (not recommended, neither from a usability nor security point of view).
- Wait and see: Inform the users that the service is temporarily unavailable and encourage them to try again later. Wikipedia has an example of this implemented in PHP.
- Alert an operator: A manual task is created for an operator. For example, to check whether the RSS feed has been moved to a new address.
- Empty response: We return an empty response. For example, if the response from a service is used for displaying product recommendations on a website, then we can return an empty list and let the UI act as if there were no product recommendations.
- Default response: We return a safe default response. For example, in an insurance claims process, we can default the fraud risk to high, to be on the safe side, but otherwise continue with the automated process.
- Cached response: We return the last successful response. Like in the example with the newsreader earlier in this post.
- Degraded response: We use local data to generate a lower quality response as a substitute for the real one. For example, in the insurance claims process in the previous bullet then if it’s a VIP customer who hasn’t reported a claim during the last year and the claim amount is less than $1,000 then we consider the fraud risk as being low.
- Eventual consistency: We will synchronize the systems later. For example, if our web shop cannot access the inventory system, we will still take the customer’s order, put the request in a queue, and update the inventory system when it eventually becomes available again.
The right fallback strategy is almost always a business decision. For example, issuing motor insurance policies based on partial information may be an unacceptable risk and a wait and see strategy should be used. But for a web shop it may be a better fallback strategy to accept the customer’s order, without knowing if we are able to fulfill it, and then send a gift certification if we later realize that we cannot fulfill the order.
That’s it. I hope you enjoy this short post about a design pattern that doesn’t get all the attention that it deserves.
Hi Ken! In the Wikipedia article you refer in “Wait and see”, wouldn’t it be better to use the following approach (since you you no longer need to cron job?)
Best,
Tommy
The difference is that if the MySQL database is under heavy pressure due to many concurrent connection requests, then the code snippet above will not give the DB much breathing space; whereas, the Wikipedia example will give some breathing space (the exact period will depend on crontab settings).
/Kenneth